Publications
Conference & Journal Articles
2026
-
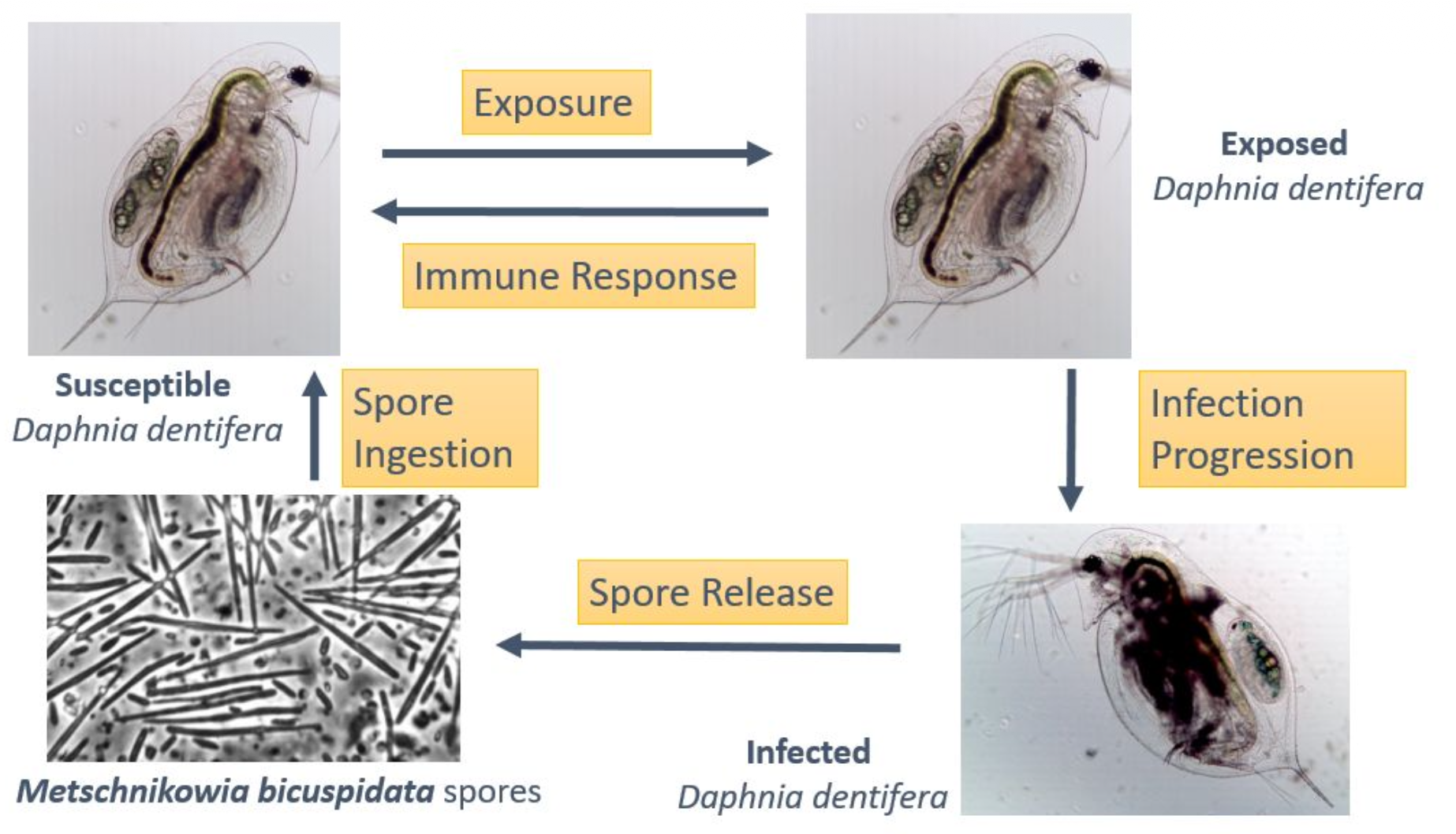 The Role of Host Immunity and the Environment in Seasonal Disease DynamicsGabriel Kosmacher, Dillon Max, Zoi Rapti, and 2 more authorsBulletin of Mathematical Biology, Jan 2026
The Role of Host Immunity and the Environment in Seasonal Disease DynamicsGabriel Kosmacher, Dillon Max, Zoi Rapti, and 2 more authorsBulletin of Mathematical Biology, Jan 2026In both human and wildlife disease systems, temporal shifts in host immunity may shape the timing and severity of epidemics. Yet, immune responses, as well as seasonal patterns in their expression, are difficult to measure. Rather, field studies collect phenomenological data on infection outcomes. Pairing epidemic data of multiple outbreaks with models that directly parameterize immune metrics can be a powerful approach for exploring the role of time-varying immunity on disease. Field data can be used to determine how well a parameterized model can reproduce trends and differences observed among outbreaks.
2024
-
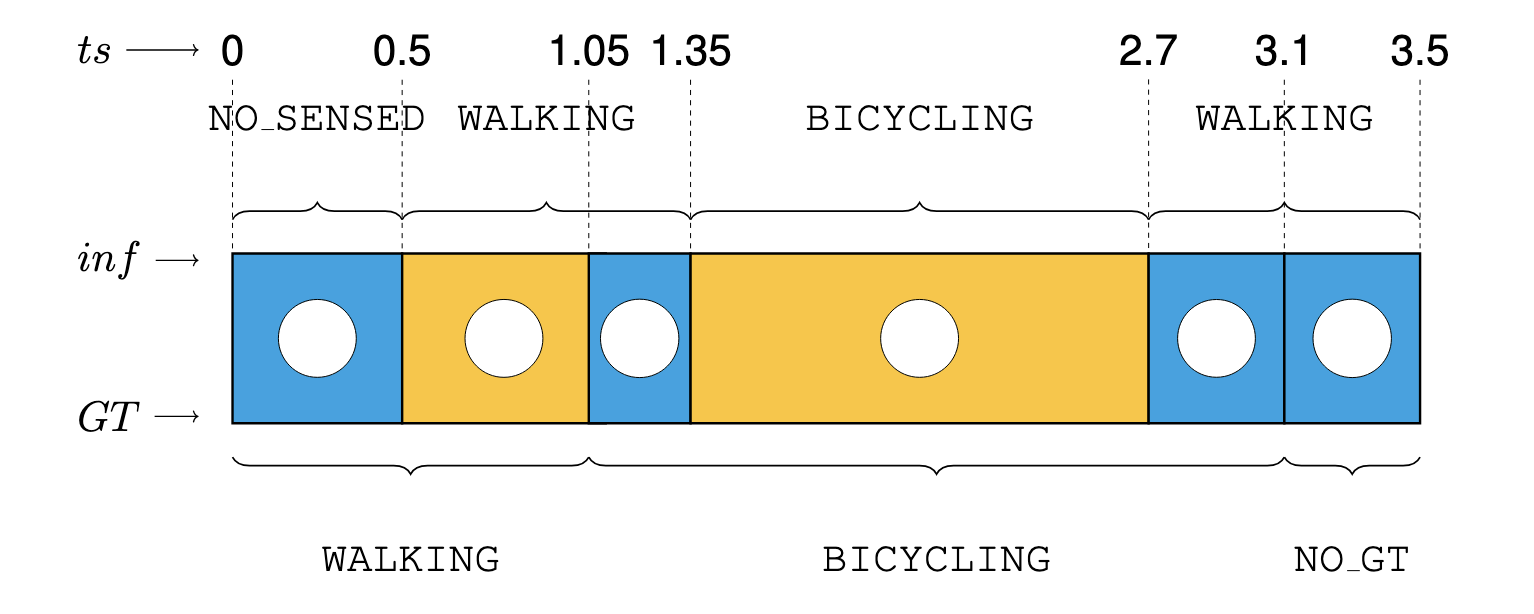 Evaluating the Interplay between Trajectory Segmentation and Mode Inference ErrorGabriel Kosmacher, and K. ShankariTransportation Research Record: Journal of the Transportation Research Board, Jul 2024
Evaluating the Interplay between Trajectory Segmentation and Mode Inference ErrorGabriel Kosmacher, and K. ShankariTransportation Research Record: Journal of the Transportation Research Board, Jul 2024Travel behavior changes are essential to transportation decarbonization. Travel diaries, consisting of sequences of trips between places, are typically used to instrument human travel behavior. However, these diaries are only as accurate as the underlying methods used to construct them. Travel diary algorithms have been a popular research topic since the advent of Global Positioning System (GPS) tracking surveys. These algorithms have typically been validated using prompted recall of presegmented trips, thus disregarding the continuity of mode inference. Phone operating systems have adopted battery-conserving techniques, but the resulting data collection errors have not been studied extensively. We introduce a framework to evaluate accuracy of trip length computations and mode inference by analyzing continuous mode-segmented trajectories for groups of trips. We then use the framework to identify the input data quality and the impact of postprocessing. Our primary inputs to this evaluation are MobilityNet, a public dataset containing information from three artificial timelines covering 15 different travel modes, and sample open-source travel diary creation algorithms from the OpenPATH project. Our framework concretely shows the variance of the distance error drops from (0.217, 0.0848) to (0.011, 0.0407) (Android, iOS) after postprocessing. Similarly, weighted F-scores for mode inference increase from (0.25, 0.29) to (0.60, 0.74) (iOS, Android) between random forest and Geographic Information Systems (GIS)-based models. We hope that this standardized method will be adapted to evaluate other, potentially proprietary, travel diary algorithms. The results can be used to understand and improve the state of the art in the travel diary creation field.
2023
-
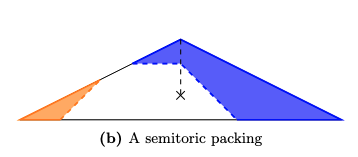 Packing Densities of Delzant and Semitoric PolygonsYu Du, Gabriel Kosmacher, Yichen Liu, and 5 more authorsSIGMA. Symmetry, Integrability and Geometry: Methods and Applications, Oct 2023
Packing Densities of Delzant and Semitoric PolygonsYu Du, Gabriel Kosmacher, Yichen Liu, and 5 more authorsSIGMA. Symmetry, Integrability and Geometry: Methods and Applications, Oct 2023Exploiting the relationship between 4-dimensional toric and semitoric integrable systems with Delzant and semitoric polygons, respectively, we develop techniques to compute certain equivariant packing densities and equivariant capacities of these systems by working exclusively with the polygons. This expands on results of Pelayo and Pelayo-Schmidt. We compute the densities of several important examples and we also use our techniques to solve the equivariant semitoric perfect packing problem, i.e., we list all semitoric polygons for which the associated semitoric system admits an equivariant packing which fills all but a set of measure zero of the manifold. This paper also serves as a concise and accessible introduction to Delzant and semitoric polygons in dimension four.
Preprints
2025
-
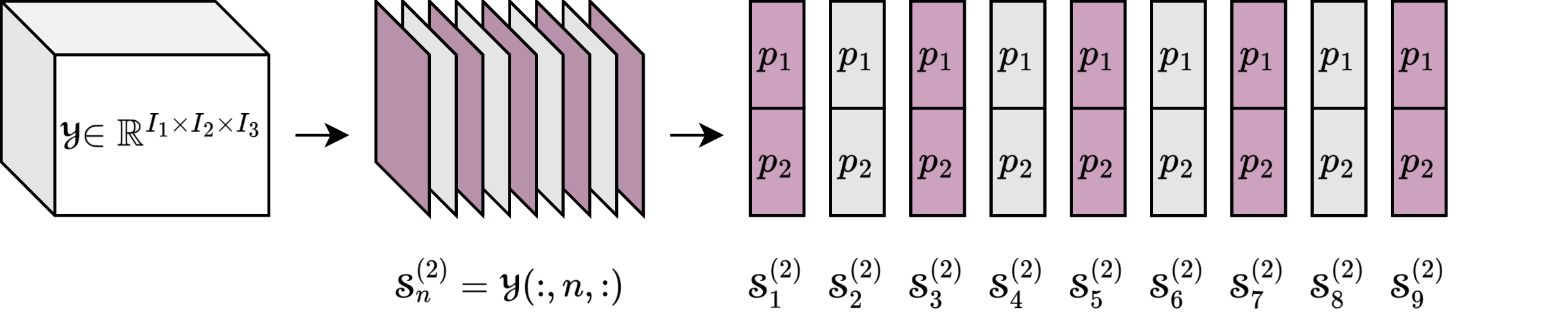 A Performance Portable Matrix Free Dense MTTKRP in GenTenGabriel Kosmacher, Eric T. Phipps, and Sivasankaran Rajamanickam2025
A Performance Portable Matrix Free Dense MTTKRP in GenTenGabriel Kosmacher, Eric T. Phipps, and Sivasankaran Rajamanickam2025We extend the GenTen tensor decomposition package by introducing an accelerated dense matricized tensor times Khatri-Rao product (MTTKRP), the workhorse kernel for canonical polyadic (CP) tensor decompositions, that is portable and performant on modern CPU and GPU architectures. In contrast to the state-of-the-art matrix multiply based MTTKRP kernels used by Tensor Toolbox, TensorLy, etc., that explicitly form Khatri-Rao matrices, we develop a matrix-free element-wise parallelization approach whose memory cost grows with the rank R like the sum of the tensor shape O(R(n+m+k)), compared to matrix-based methods whose memory cost grows like the product of the tensor shape O(R(mnk)). For the largest problem we study, a rank 2000 MTTKRP, the smaller growth rate yields a matrix-free memory cost of just 2% of the matrix-based methods, a 50x improvement. In practice, the reduced memory impact means our matrix-free MTTKRP can compute a rank 2000 tensor decomposition on a single NVIDIA H100 instead of six H100s using a matrix-based MTTKRP. We also compare our optimized matrix-free MTTKRP to baseline matrix-free implementations on different devices, showing a 3x single-device speedup on an Intel 8480+ CPU and an 11x speedup on a H100 GPU. In addition to numerical results, we provide fine grained performance models for an ideal multi-level cache machine, compare analytical performance predictions to empirical results, and provide a motivated heuristic selection for selecting an algorithmic hyperparameter.